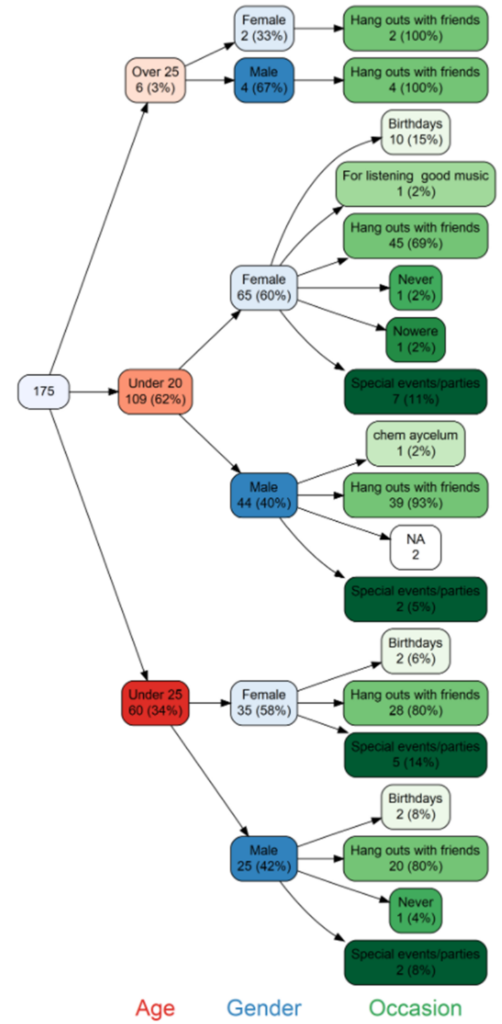
Puudiagrammi on kätevä työkalu, jota voidaan hyödyntää esimerkiksi kyselytutkimuksen analysoinnissa. Puudiagrammi kuvaa selkeästi muuttujien jakautumista sekä näyttää lisäksi niiden arvot ja frekvenssit.
Kuva 1. Esimerkki puudiagrammista
Puudiagrammin tekoon löytyy ohjeistus: Introduction to vtree(Barrowman 2021). Barrowmanin opas toimi pohjana puudiagrammin luomisessa R-Studiolla.
Data
Puudiagrammi toimii parhaiten tarkasteltaessa epäjatkuvia muuttujia. Kyseistä diagrammia luodessa käytettiin Armeniassa sijaitsevien anniskeluravintoloiden ja niihin kohdistuneen kyselytutkimuksen tuloksia (Hambardzumyan. 2017). Yllä olevassa puudiagrammissa on esiteltynä vastaajien sukupuoli, ikä ja syy käydä ravintolassa.
Puudiagrammien tarkastelussa tulee muuttujien arvojoukkojen olla riittävän suppeita. Tarkasteltaessa jatkuvia muuttujia arvojoukot saattavat hyvin usein olla liian laajoja. Tästä syystä muuttujat kannattaa muuntaa epäjatkuviksi muuttujiksi. Tässä tapauksessa esimerkiksi ikä oli jatkuva muuttuja, joka muunnettiin ikäluokaksi.
Diagrammin luominen käytännössä
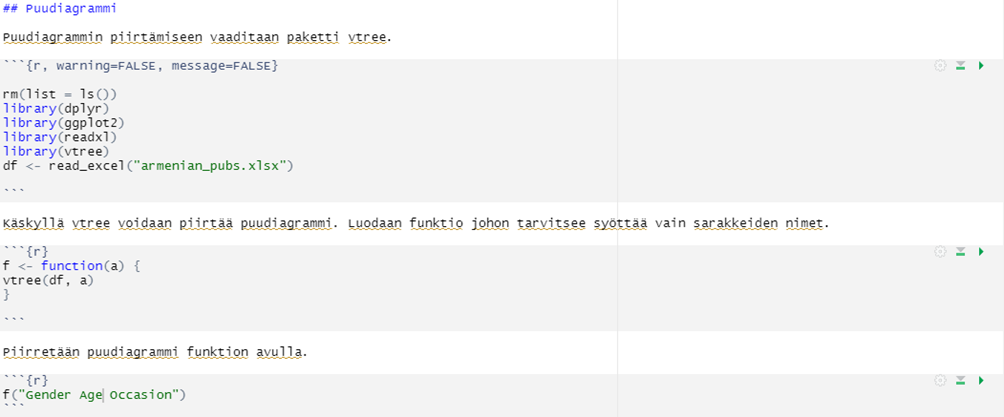
Puudiagrammin luominen R-Studiossa on yksinkertaista ja funktion avulla vielä yksinkertaisempaa ja nopeampaa. Funktion luominen mahdollistaa sen, että käytännössä käskytykseen tarvitsee syöttää vain halutut sarakkeet, eli muuttujat, joita puudiagrammin avulla halutaan tarkastella.
Kuva 2. Puudiagrammin luominen.
Käytännön kannalta ongelmallista oli, että puudiagrammia ei saatu näkymään muuten, kuin kääntämällä RMD-tiedosto HTML-tiedostoksi. Tarvittaessa puudiagrammi saadaan kopioitua esimerkiksi Word-tiedostoon. Puudiagrammi on myös kuvana iso, joten muuttujien lisääntyessä kannattaa puudiagrammi piirtää pitkittäin. Poikittain piirrettäessä arvojen ja frekvenssien tarkastelu voi olla vaikeaa sillä kuva on pieni.
Tulevaisuudessa hyödyllistä olisi myös luoda työkalu, jolla R-kieltä osaamatonkin henkilö kykenee luomaan puudiagrammin esimerkiksi Excel-taulukon pohjalta.
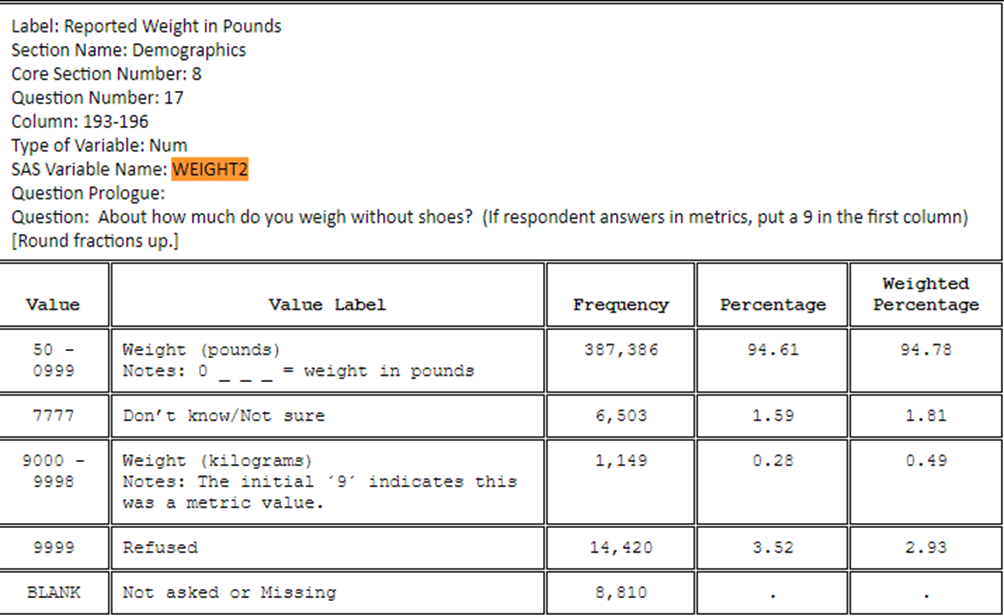
BRFSS-data on kyselytutkimusainestoa vuodelta 2019, jossa on tutkittu Yhdysvaltain kansalaisten terveyttä ja elintapoja. Data on taulukkomuodossa XPT-tiedostona ja sitä oli noin 400 000 riviä ja yli 300 saraketta. Data on saatavissa täältä (CDC. 2020).
Tehtävänä oli muokata datasta lyhyempi ja selkeämpi kokonaisuus, jota voi käyttää esimerkiksi opetuksessa ilman, että datan muokkaamiseen tarvitsee käyttää paljoa aikaa. Datan käyttö edellyttää jonkin tapaista muokkausta, sillä alkuperäisen datan arvojen tulkitseminen vaatii erillisen tulkintaa varten tehdyn tiedoston (CDC. 2020). Esimerkiksi kyselytutkimuksessa osa vastaajista oli antanut painonsa nauloina ja osa taas kilogrammoina. Lisäksi joukosta löytyi vastaajia, jotka eivät halunneet kertoa painoa tai kohta on jätetty tyhjäksi.
Datan muokkaus alkoi sillä, että valittiin tiedot, joihin selkeytetty data haluttiin rajata. Yhteensä uuteen dataan kerääntyi saraketietoja noin 30 kappaletta ja rivitietoja rajausten jälkeen oli noin 300 000. Uuteen ja rajattuun dataan valitut tiedot olivat haastateltavan joukon perustietoja (pituus, paino, sukupuoli yms.), alkoholin käyttöön liittyvät vastaukset sekä tupakointiin liittyvät vastaukset.
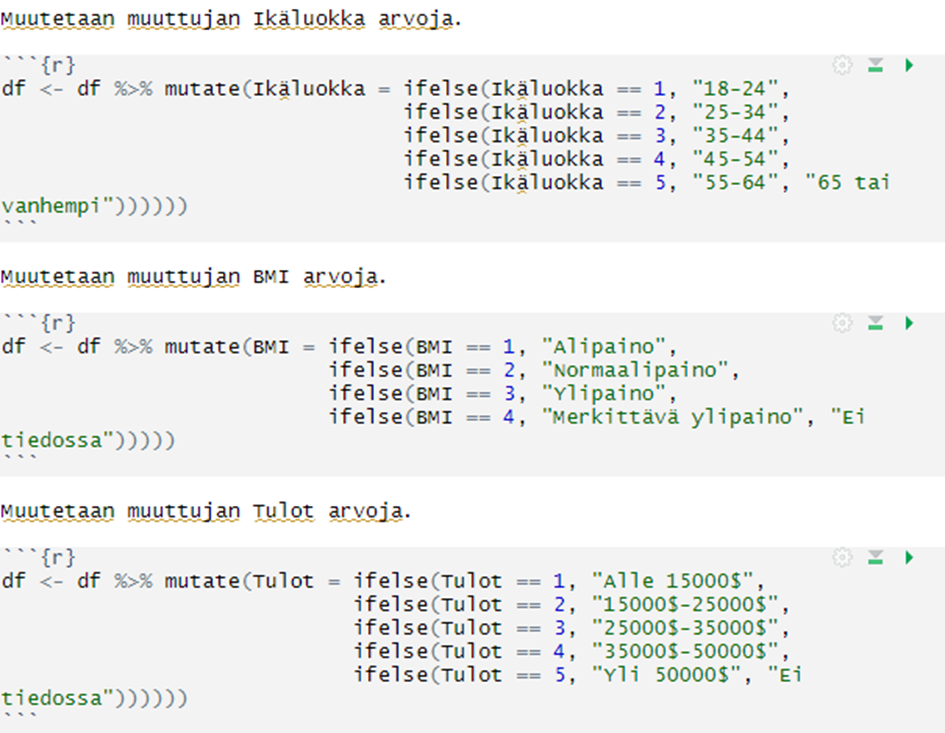
Itse konkreettinen datan muokkaus oli suurimmilta osin vain arvojen määrittämistä uudelleen. Datan oli tarkoitus koostua sopivassa suhteessa sekä jatkuvista ja epäjatkuvista muuttujista. Lisäksi data käännettiin suomen kielelle. Työkaluna datan käsittelyssä toimi R-studio.
Kuva 2. Arvojen muokkausta.
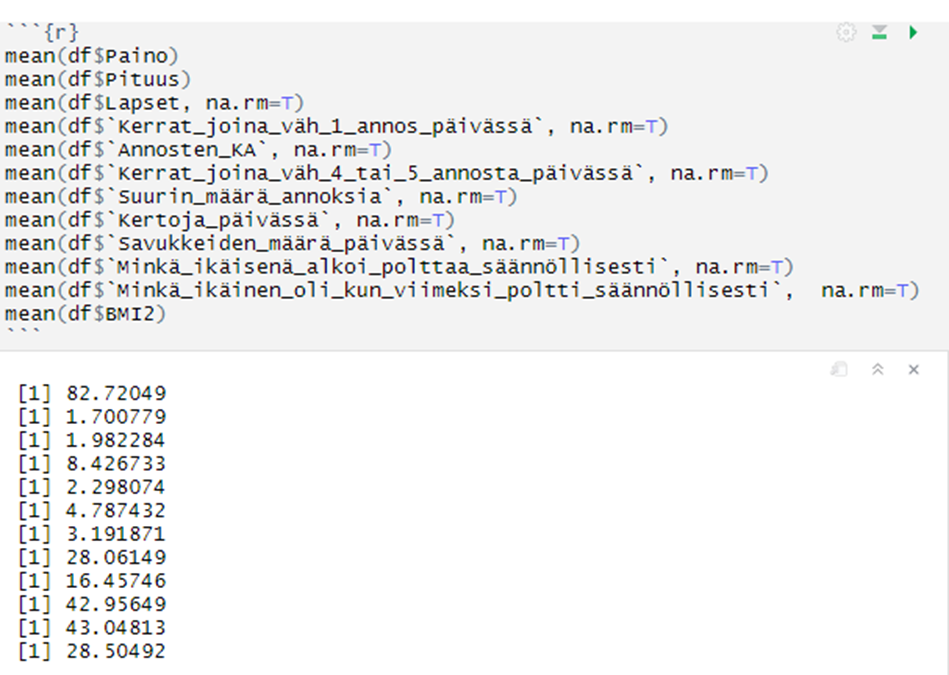
Lopuksi uusi data tallennettiin omaksi R-tiedostoksi, josta sen voi muuntaa tarvittaessa esimerkiksi Excel-tiedostoksi ja testattiin datan toimivuutta laskemalla jatkuvien muuttujien keskiarvot. Lisäksi muokatulle versiolle tehtiin myös Word-tiedosto, johon kirjattiin kaikki muuttujien nimet ja niiden arvojoukot. Muokatusta datasta tehtiin myös lyhennetty versio, jossa muuttujien nimet on lyhennetty.
Tässä blogitekstissä kerrotaan miten redditistä voi kerätä dataa käyttämällä yksinkertaista python ohjelmaa. Sen käyttö ei vaadi koodausosaamista, riittää jos osaa tehdä python asennuksen ja avata tiedoston mukana tulevalla työkalulla.
Datan keräämiseen tarvitaan siis python-ohjelmointikielen asennus tietokoneelle. Kätevän ja jokseenkin pöhöttyneen ratkaisun tarjoaa Anaconda ja sen voi asentaa tietokoneelleen täältä.
Kun kärmes on asennettu, voidaan siirtyä datan keräämiseen. Tässä esimerkissä käytetään Pushshift APIa sekä sille räätälöityä python kirjastoa nimeltä psaw. Jos ei jaksa lukea blogitekstiä niin koodi löytyy datalabin githubista täältä.
Psaw-kirjasto täytyy asentaa ennen sen käyttämistä. Anacondan (ja vähemmän pöhöttyneen minicondan) mukana tulee python pakettien asentaja nimeltä pip, ja tarvittavan paketin voi asentaa kirjoittamalla anacondan komentoriville komento pip install psaw
anaconda komentorivin käynnistys windows koneella
Vihko
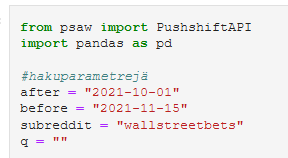
Koodi on kirjoitettu internet-selaimessa pyörivään Jupyter-vihkoon. Sen voi käynnistää joko anacondan valikosta tai kirjoittamalla jupyter notebook promptiin. Githubista löytyvän vihkon voi avata omalla koneella ja tehdä redditiin hakuja muuttamalla hakuparametrejä mieleisekseen (ja lisäämällä uusia). Pushshift API tarjoaa useita tapoja rajata haettavaa dataa. Esimerkiksi parametrillä q voi postauksen otsikkoon tai tekstiin kohdistaa sanahakuja, mutta tässä käytetään vain seuraavia parametrejä:
after: ajankohta jonka jälkeen postauksia haetaan (VVVV-KK-PP)
before: ajankohta johon asti postauksia haetaan
subreddit: alareddit josta haetaan
testihaussa käytetyt hakuparametrit jupyter vihkossa
Haku tehdään postausten (submission) endpointiin ja kohdennetaan r/wallstreetbets alaredditiin. Se on aktiivinen yhteisö joka tunnetaan mm. äkillisestä innostuksesta ostaa Gamestop-yrityksen osaikkeita alkuvuodesta 2021.
Testissä haetaan postauksia puolentoista kuukauden ajalta lokakuun alusta marraskuun puoleenväliin 2021 ja niitä löytyi hieman yli 41 000, eli n.900 kpl/päivä.
Nopeata tarkastelua varten postausten data laitetaan Pandas-kirjaston avulla luotuun taulukkoon. Esimerkissä taulukko on nimetty nimellä df, joka on lyhenne sanoista DataFrame. Pandas kirjasto löytyy valmiina anacondasta. Taulukon voi muuttaa helposti esimerkiksi csv-tiedostoksi komennolla df.to_csv('myRedditDataCsv.csv')
Palkkikaavio
Seuraavaksi dataa analysoidaan värikkäällä palkkikaaviolla. Redditissä postauksella voi olla ”flair” joka on käyttäjän sille lisäämä luokittelu ja josta käy ilmi postauksen aihe. Joissain alaredditeissä sellainen vaaditaan kun taas joissain sitä ei käytetä ollenkaan. Kerätyssä datassa flair on muuttuja nimeltä "link_flair_text” ja pandas-taulukosta voi nopeasti tarkastaa, että kerätyissä postauksissa kyseinen sarake saa vain 15 Null -arvoa. Tämä kertoo siitä että kyseisessä alaredditissä postausten merkitseminen flairilla on todennäköisesti pakollista.
Eri flairien määrät on visualisoitu aina trendikkäällä palkkikaaviolla.
flairien määrärt kerätyissä postauksissa
Tuloksista näkee, että flaireja on postausten määrään nähden vähän, mikä todennäköisesti johtuu siitä että ne valitaan valmiista listasta eikä niitä voi keksiä itse.
Koodi löytyy siis Xamkin datalabin githubista. Onnistuneen python asennuksen jälkeen koodia voi pyörittää omalla koneella painamalla play-nappia. API:n avulla voi selvittää esimerkiksi miten monta kertaa iltasanomien url on jaettu Redditissä,kerätä kaikki kuva-urlit r/historymemes -yhteisöstä tai vaikka kaikki koronamegaketjuihin tehdyt kommentit.
Viime blogissa kirjoitimme, kuinka saatiin käyttöömme oma SQL-database. Seuraavaksi tuli aika hyödyntää sitä opetuskäyttöön.
Projekti alkoi Raspberry Pi:n ja siihen kytkettävän sensorin tilaamisella. Pi:hin ladattiin oma Raspbian Os käyttöjärjestelmä ja varmistettiin, että sensori toimii ja kerää dataa. Tehtävänä oli mitata lämpötilaa, ilmankosteutta ja ilmanpainetta. Pi kuitenkin lämmitti sensoria, joten lämpötilan arvo vääristyi. Realistista arvoa varten tarvittiin johto, joka mahdollisti sensorin erille laittamisen Pi:stä. Tässä vaiheessa huomasimme, että tarvitsemme ulkopuolisia palveluja datan keräämistä varten.
NodeRed ja Azure IoT Central
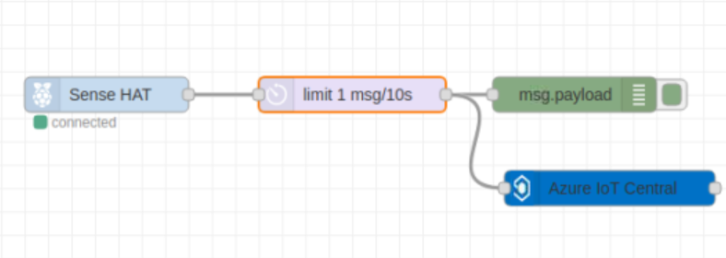
Pi:lle ladattiin NodeRed lisäohjelma. Ohjelmassa spesifioitiin Pi:n IP osoite ja Pi yhdistettiin verkkoon. NodeRedin selaimessa määriteltiin kytkentäkaavio. Kaavion tarkoituksena oli aluksi käynnistää SenseHat ja sen jälkeen siirtää kerätty data Azuren IoT Centraliin.
Pian kuitenkin huomasimme, että Noden kerättyä dataa ei IoT Centralista pystynyt viemään SQL palvelimelle. Toiveena oli, että IoT Central päivittää siirretyt datat samaan tiedostoon. Siirretty data loi kuitenkin jokaisen siirron jälkeen uuden tiedoston, joten sen siirtäminen SQL palvelimelle ei ollut mahdollista.
Seurauksena NodeRed ja IoT Central hylättiin ja päätettiin siirtyä Azuren sisäisiin palveluihin.
Azuren palvelut datan keräämiseksi
Pi:lle vaadittavien ohjelmien asentamista varten tarvittiin Windows käyttöjärjestelmällä toimiva kone. Koneella oli tarkoitus kirjoittaa koodi, jolla saataisiin Pi yhdistämään Azuren IoT hubiin. Koodi myös siirtäisi sensorin avulla kerättyä dataa Azureen.
Ensimmäisenä ohjelmana asennettiin Visual Studio Code. Studioon asennettiin vaaadittavat lisäosat. Seuraavaksi asennettiin DotNet Core, Node.js, Azure Functions Core Tools, Azure Storage Explorer ja Putty.
Käyttöönotto alkoi koodaamisella. Visual Studioon kirjoitettiin C# koodi. Koodiissa määriteltiin sensorin asetukset. Asetukset koskivat esimerkiksi lämpötilan yksikköä ja kuinka usein sensori keräisi dataa. Myös kellonaika määriteltiin paikallisen kellonajan mukaiseksi. Jotta laite osaisi yhdistää Azure IoT hubiin, lisättiin sen avain.
Asetuksien määrittämisen jälkeen oli aika siirtää koodi Pi:lle. Siirtäminen tapahtui Node.js ohjelman avulla. Aluksi määriteltiin siirettävän tiedoston parametrit. Tiedosto puhdistettiin ja varmistettiin sen moitteeton toimivuus. Mikäli tiedostossa olisi virheitä, ohjelma ilmoittaisi siitä välittömästi.
Toimivuuden varmistuksen jälkeen aloitettiin tiedoston siirtäminen. Aluksi Pi:lle luotiin uusi kansio, johon tiedostot asennettaisiin. Kansion nimeksi annettiin SenseHATDotNetCore. Nodeen syötettiin koodi, joka yhdistäisi Pi:hin ja siirtäisi haluamamme tiedostot siihen.
Projektin loppusuora
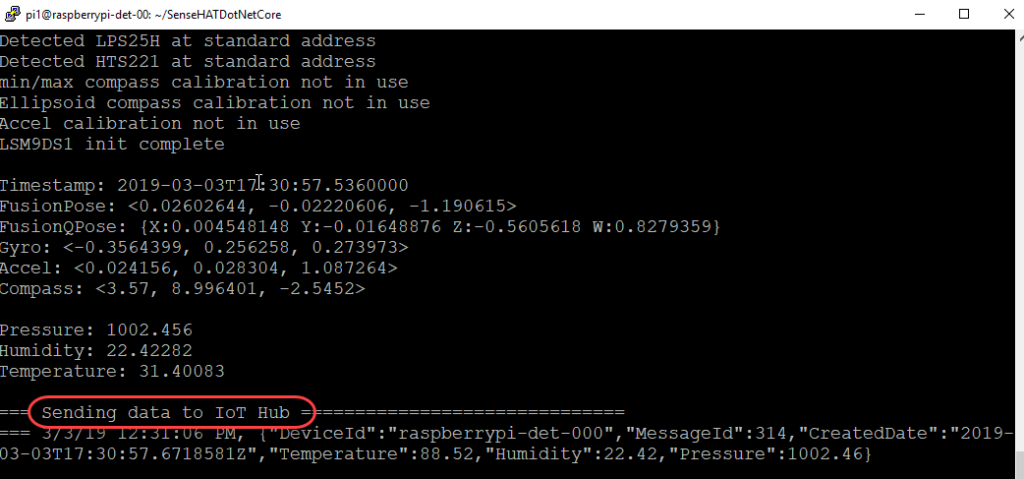
Pi:llä käynnistettiin sen oma Terminal. Terminaalissa käynnistettiin juuri siirtämämme tiedosto. Tämä onnistui ensin navigoimalla juuri luotuun kansioon. Seuraavaksi ohjelma käynnistettiin./SenseHATDotNetCore komennolla.
Juuri käynnistetty koodi toimi! Dataa siirtyi vartin välein IoT hubiin. Nyt ainoana tavoitteena oli datan siirtäminen meidän SQL palvelimelle. Tämän suoritimme Stream Analytics jobin avulla. Datan sisätuloksi määritettiin IoT hub ja ulostuloksi SQL-database.
Pi saatiin toimimaan, joten se voidaan asentaa haluamamme luokkaan. Luokassa Pi mittaa vartin välein lämpötilan, ilmankosteuden ja ilmanpaineen.
Datan analysointi
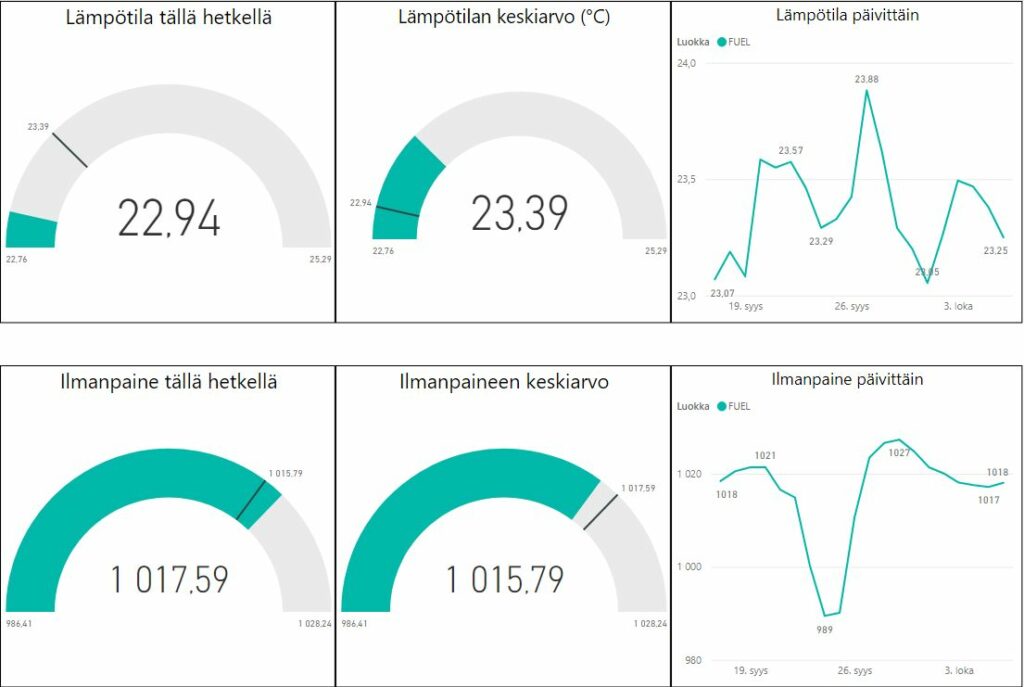
Data oli siirretty onnistuneesti SQL palvelimelle. Voitiin siis aloittaa sen analysointi. PowerBi-ohjelma valikoitui analysoinnin työkaluksi. Sensorin data avattiin ohjelmassa. Seuraavana vuorossa oli datan puhdistaminen. Esimerkiksi, ilmankosteus muutettiin prosenteiksi, päivämäärä ja aika yhdistettiin. Datan käsittelyn jälkeen rakennettiin visualisoinnit, joista ilmenee mm. tämänhetkinen lämpötila, päivittäinen ilmankosteus ja ilmanpaine.
Mitä jatkossa?
Lähes kaikki tavoitteet saatiin suoritettua. Dataa kerääntyy ja sitä voidaan käyttää opetuksessa. Oppilaat voivat harjoitella esimerkiksi datan siivoamista ja analysointia. Myös koodaamisesta kiinnostuneet voivat Pi:llä testata osaamistaan.
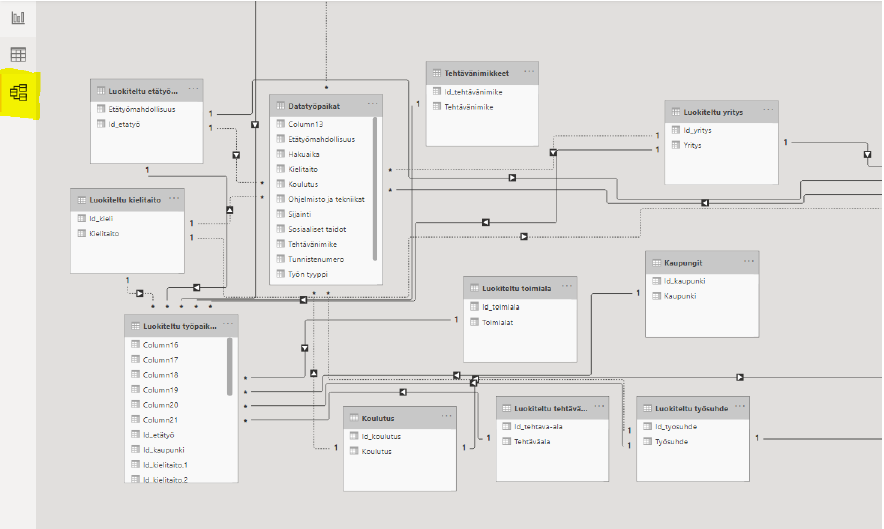
Data-analytiikan ja visualisoinnin koulutuksen viidennellä lukukaudella toteutetaan ja raportoidaan tilaajalle laaja data-analytiikan tutkimus- ja kehitysprojekti. Työparini Emman kanssa saimme Xamkin DataLABilta tehtäväksemme kerätä tietoa datatyöpaikkojen tilanteesta ja kehityksestä Suomessa sekä analysoida ja visualisoida kerätty data Microsoftin Power BI-työkalulla. Tavoitteena oli myös rakentaa datatyöpaikoista mittaristo DataLABin käyttöön. Projektin tuotoksena syntyneen datatyöpaikkojen osaamistarvekartoituksen avulla data-analytiikan koulutusta voidaan kehittää entistä paremmin vastaamaan tämän hetken työelämän tarpeita ja vaatimuksia.
Datan kerääminen
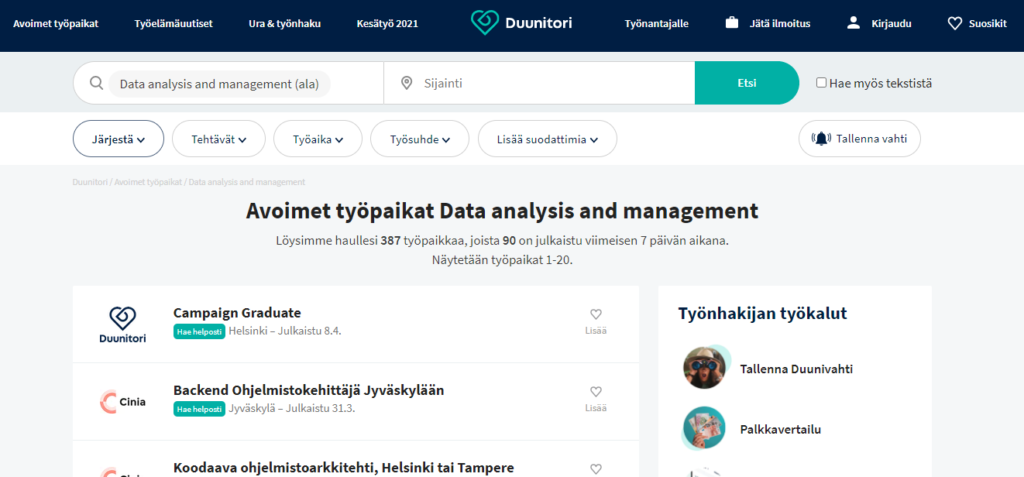
Projektissa käytettävä data rajattiin kerättäväksi yhdeltä internetin työnhakusivustolta ja tavoitteena oli kerätä tietoja sadasta datatyöpaikasta Suomessa. Työnhakusivustoksi valittiin Duunitori.fi, josta hakusanalla ”data-analysis and management” kerättiin työpaikkailmoituksista manuaalisesti Excel-tiedostoon tarvittavat tiedot. Muuttujiksi määriteltiin tehtävänimike, yritys, sijainti, työn tyyppi, työsuhde, koulutus, etätyömahdollisuus, ohjelmisto ja tekniikat, kielitaito sekä sosiaaliset taidot. Projektidata kerättiin lokakuussa 2020, jolloin projektin lopputulokseen vaikutti sillä hetkellä saatavilla oleva data datatyöpaikoista.
Kuvakaappaus Duunitori.fi:n hakunäkymästä
Muuttujien luokitteleminen
Projektidatan keräämisen jälkeen oli vuorossa datan siivous ja muuttujien luokitteleminen. Tässä vaiheessa mietittiin, kuinka kerättyä dataa on järkevintä lähteä hyödyntämään. Esimerkiksi datavarastona toimivaan Excel-tiedostoon kirjattu ”yritys”-muuttuja otettiin jatkokäyttöön luokiteltuna muuttujana ”Luokiteltu toimiala”. Id-numerot ja muuttujaluokitukset kerättiin omille välilehdilleen datavaraston sisällä. Mittariston rakentamisen kannalta päätettiin välilehdestä ”Luokiteltu työpaikka” tehdä päätaulu. Tälle välilehdelle kerättiin mittaristoa varten tarvittavien muuttujien id-numerot kutakin datariviä koskien. Näin haluttiin varmistaa tietojen linkityksen onnistuminen jatkotyöskentelyä varten. Viiteavaimena välilehdelle Datatyöpaikat toimi muuttuja Id_työpaikka. Tällä id:lla pystyttiin linkittämään Datatyöpaikat-välilehdelle syötetty työpaikka välilehdelle ”Luokiteltu työpaikka”. Jokainen rivi edusti erillistä työpaikkaa ja muuttujien arvot kerättiin omiin sarakkeisiinsa. Muuttujat saivat arvoja työpaikkailmoituksessa esiintyvän tekstisisällön mukaan.
Tietomallien rakentaminen
Kun haluttu data oli saatu kerättyä Excel-tiedostoon, oli vuorossa datan tuonti Microsoft Power BI -työkaluun. Työt Power BI -työkalun sisällä lähtivät liikkeelle tietomallien rakentamisesta, eli taulujen välisten suhteiden luomisesta. Tässä projektissa päätauluna tietomalleissa toimi taulu ’Luokiteltu työpaikka’. Muista tauluista on linkitetty asianmukaiset suhteet tähän päätauluun.
Projektin tietomallit Power BI:ssä
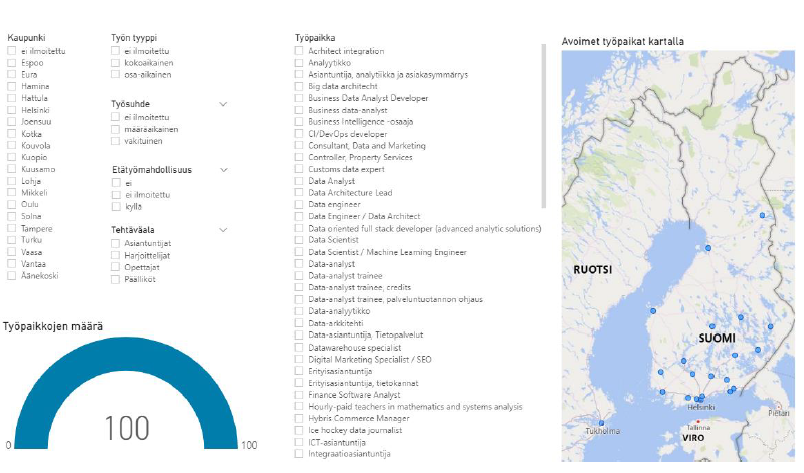
Tiedon visualisointi/mittariston rakentaminen ja tiedon analysointi
Power BI:ssä työ jakautui mittariston rakentamiseen sekä mittariston ulkopuolisten visualisointien tuottamiseen. Visualisointi haluttiin pitää mahdollisimman selkeänä ja yksinkertaisena, minkä pohjalta tehtiin valinnat fontti- ja värivalintojen suhteen. Myös mittaristo päätettiin rakentaa mahdollisimman selkeäksi ja helppokäyttöiseksi. Mittaristo on toteutettu omalle välilehdelleen raporttinäkymässä ja siihen valittiin työpaikkojen suodatuksen kannalta oleellisimmat tiedot: kaupunki, työn tyyppi, työsuhde, etätyömahdollisuus, tehtäväala, työpaikka, karttanäkymä sekä työpaikkojen määrä mittarimuodossa.
Mittaristo datatyöpaikoista
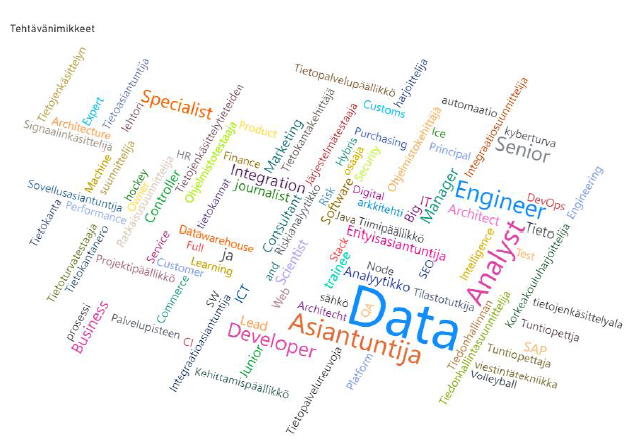
Mittariston ulkopuolisissa visualisoinneissa käytettiin enimmäkseen palkkikuvioita. Joidenkin muuttujien kohdalla visualisoinnissa käytettiin sanapilveä, joka tuotiin lisävisualisoinniksi Microsoft App Sourcesta. Mittariston rakentamisen ja tiedon visualisoinnin jälkeen dataa lähdettiin analysoimaan Power BI:stä saatujen kuvaajien pohjalta.
Projektin lopputulokset ja johtopäätökset
Projektin lopputuloksina esiteltiin saadut tulokset datatyöpaikkojen sijainnista, etätyömahdollisuudesta, työtyypistä, työsuhteesta, tehtävänimikkeistä, työpaikoista toimialoittain ja tehtäväaloittain, koulutusvaatimuksista, teknisen osaamisen vaatimuksista, henkilökohtaisista, ammatillisista ja sosiaalisista taidoista sekä kielitaidosta.
Yhteenvetona todettiin, että datatyöpaikkoja oli hyvin tarjolla. Eniten työpaikkoja oli avoinna pääkaupunkiseudulla, mutta etätyömahdollisuuksien yleistyessä työ ei välttämättä ole paikasta riippuvaista. Koulutusvaatimuksena esiintyy yleisesti korkeakoulututkinto ja teknisinä vaatimuksina hakijoilta toivotaan ohjelmointi-, tietokanta- ja BI-työkaluosaamista. Englannin ja suomen kielten (tässä järjestyksessä) osaaminen on vaatimus valtaosassa työpaikkoja. Hakijoilta edellytetään mm. yhteistyö- ja vuorovaikutustaitoja, oppimishalukkuutta sekä itseohjautuvuutta.
Tehtävänimikkeet sanapilvenä esitettynä
Teorian ja saatujen tulosten perusteella voidaan olettaa, että datatyöpaikkojen määrä tulee kasvamaan alasta riippumatta. Datatyöpaikkoja tukevaa koulutustarjontaa tulisi lisätä niin yliopistoissa kuin ammattikorkeakouluissa. Opiskelijoille tulisi tarjota laajemmin koulutusta tilastotieteen, ohjelmoinnin ja liiketoimintaopintojen yhdistelmänä.
Kehitysehdotuksena tilaajalle ehdotimme, että Xamk tarjoaisi data-analytiikan opiskelijoille enemmän matematiikan ja tilastotieteen opetusta sekä ohjelmointia. Koulutuksessa voisi olla selkeät suuntautumisvaihtoehdot kuten ohjelmointi, tilastotiede tai visualisointi. Myös DataLAB voi olla konkreettisesti mukana syventämässä data-analytiikan opintoja tarjoamalla monipuolisesti erilaista opintosisältöä.
Teknologian kehittymisen ja digitalisaation myötä datan määrä kasvaa maailmassa valtavalla vauhdilla ja yrityksillä on käytettävissään paljon sekä sisäistä että ulkoista tietoa. Tiedolla ei kuitenkaan ole merkitystä, jos se ei johda mihinkään toimenpiteisiin tai sitä ei voi hyödyntää päätöksenteossa. Datan jalostaminen informaation kautta tiedoksi, tiedon analysointi ja tiedon hyödyntäminen päätöksenteossa vaikuttavat tänä päivänä yhä enemmän yritysten menestymiseen. Tällöin puhutaan todennettuun tietoon perustuvasta päätöksenteosta ja tiedolla johtamisesta.
Tietojohtaminen voidaan määritellä tietoon liittyviin johtamiskysymyksiin erikoistuneena tietoyhteiskunnan johtamisen ajattelutapana/suuntauksena. Se toimii eräänlaisena kattokäsitteenä tietämyksenhallinnan, organisaation oppimisen, tietohallinnon, aineettoman pääoman sekä liiketoimintatiedon hallinnan osa-alueille ja liittyy läheisesti tietojärjestelmä- ja johtamistieteisiin.
Tietojohtamisella tarkoitetaan aineettomiin resursseihin, kuten tietoon ja osaamiseen perustuvaa arvon luomista. Se sai alkunsa informaatiovallankumouksen myötä 1980-1990 -luvuilla. Tietojohtamista tarvitaan kaikkialla missä ihmiset toimivat yhdessä jonkin tavoitteen eteen. Koska kaikkea tietoa ei voi hallita, se on myös tiedon luomiselle ja jakamiselle otollisten olosuhteiden luomista.
Tietojohtamisen tavoitteena on saavuttaa pysyvää kilpailuetua yhdistelemällä tietoa ja osaamista verkostoissa, kehittää tuottavuutta ja uudistumiskykyä sekä luoda avoimia tietoympäristöjä, joiden avulla tehdään yhteistyötä, käsitellään, analysoidaan, yhdistellään ja sovelletaan tietoa.
Tietojohtamista tarvitaan, koska arvoa luodaan yhä enemmän aineettomista voimavaroista. Taustalla on myös muuttunut johtamiskäsitys, jonka painopiste on osaamisen ja ainutlaatuisen kokemuksellisen tiedon johtamisessa. Kaiken toiminnan ytimessä on oppiminen ja kyky jatkuvaan uudistumiseen.
Tietojohtaminen voidaan jakaa tiedon johtamiseen ja tiedolla johtamiseen. Tiedon johtaminen on inhimillisen tietämisen ja tietäjien johtamista, johon liittyy esimerkiksi tiedon jakamista, uuden tiedon luontia tai erilaisten tietovarastojen ja -virtojen hallintaa. Tiedolla johtaminen puolestaan keskittyy tiedon jalostamiseen ja hyödyntämiseen päätöksenteossa. Keskeisessä osassa tieto- ja viestintäteknologian mahdollistamien ratkaisujen lisäksi on myös tiedolla johtamisen kulttuuri eli kuinka organisaatiossa on oivallettu toimintaa ohjaavan tiedon merkitys ja yksilön rooli kokonaisuuden kannalta.
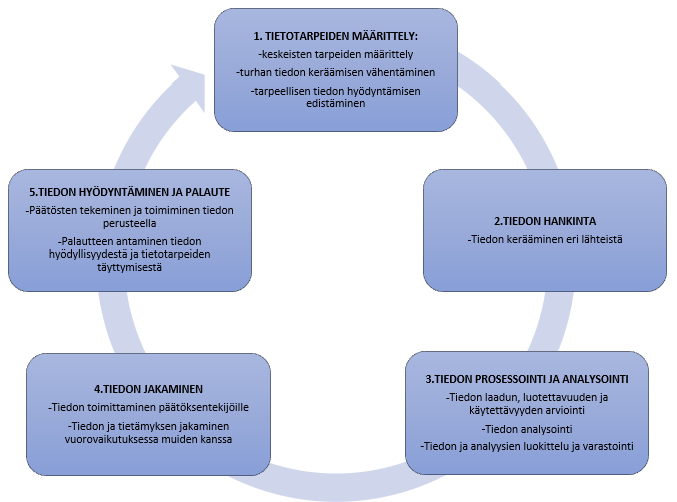
Tiedolla johtamisen prosessi
Liiketoimintatiedon hallinnan avulla organisaatio kerää, analysoi ja hyödyntää oman toimintansa kannalta tärkeää liiketoimintatietoa. Tavoitteena on tarpeelliseksi arvioidun tiedon hankkiminen, luokittelu ja varastointi eri lähteistä jatkokäyttöä varten. Se yhdistää ja analysoi näennäisesti irrallisia tiedonpalasia, jotka jalostuvat tiedoksi päätöksentekijöille. Parhaimmassa tapauksessa liiketoimintatiedon hallinta tukee päätöksentekoa proaktiivisesti antamalla ennakkovaroituksia liiketoimintatiedon tapahtumista ja niiden vaikutuksista organisaatioon, jotka mahdollistavat parempien päätösten tekemisen ja menestyksellisemmän liiketoiminnan.
Liiketoimintatiedon hallinnan prosessimalli ja keskeiset tehtävät (mukaillen Laihonen ym. 2013)
Modernin tiedolla johtamisen edellytyksiä
Kulttuuri
Avainasemassa tiedolla johtamisen johtamisen kultttuurissa on se, että henkilöstö ottaa analytiikan osaksi omaa työtään ja kokee hyötyvänsä siitä aidosti.
Osaaminen
Tiedolla johtaminen vaatii paljon teknistä osaamista, mutta tärkeintä on kuitenkin kyky ymmärtää liiketoimintaa: miksi dataa kerätään ja mitä anlytiikalla tavoitellaan.
Organisaatiorakenne
Varsinkin suurissa organisaatioissa data on usein siiloissa. Siksi on tärkeää, että organisaatioissa on data-analytiikasta vastaava henkilö, joka pystyy toimimaan yli organisaation siilorajojen.
Teknologia
Käytettävät teknologiat tulisi valita tilanteen ja liiketoimintatarpeen mukaan jo olemassa olevat ratkaisut huomioiden. Toisinaan se tarkoittaa luopumista vanhasta ja panostamista kokonaan uuteen ratkaisuun, joskus taas jo olemassa olevaa teknologiaa pitäisi pystyä hyödyntämään tehokkaammin.
Lähteet:
Advian. Mitä on tiedolla johtaminen?
Halima, T. 2015. Tiedolla johtaminen.
Kosonen, M. 2015. Tietojohtaminen ja tiedolla johtaminen.
Laihonen, H., Hannula, M., Helander, N., Ilvonen, I., Jussila, J., Kukko, M., Kärkkäinen, H., Lönnqvist, A., Myllärniemi, J., Pekkola, S., Virtanen, P., Vuori, V. & Yliniemi, T. 2013. Tietojohtaminen. Tampere: Tampereen teknillinen yliopisto.
Nykymaailma muuttuu valtavalla vauhdilla ja uusia opetusmenetelmiä tarvitaan jatkuvasti. Ennen riitti, että työntekijä osasi syöttää Exceliin numeroita ja painaa enteriä, mutta nykyään sillä ei pitkälle pääse. Teknologia kehittyy ja sen myötä tulee uusia ohjelmia, joita työntekijän on osattava käyttää ja hyödyntää. Meidän tapauksessamme tämä ohjelma oli Microsoft Azure. Azure on julkinen pilvipalvelu, jota voidaan käyttää virtuaalipalvelinten alustana. Lisäksi Azure voi toimia kehitysalustana. Azurella pystytään hallitsemaan mobiililaitteita, suojaamaan dokumentteja, analysoimaan suuria datamassoja ja luomaan esimerkiksi koneoppimista.
Mistä kaikki alkoi?
Kaikki alkoi data-analytiikan koulutuksen viidennellä lukukaudella toteutettavasta data-analytiikan tutkimus- ja kehitysprojektista. Saimme Xamkin DataLABilta tehtäväksi SQL-serverin luomisen ja käyttöoton Microsoft Azuressa. Projekti oli myös osa DataLABissa suoritettavaa syventävää harjoittelua. Tavoitteena oli saada aikaiseksi Azure-serveri, jota voidaan käyttää apuna opetuksessa sekä tehdä lyhyitä oppaita serverin luomisesta ja käytöstä.
Projektin eteneminen
Projekti alkoi hitaasti ja rauhallisesti, sillä jouduimme ensin odottelemaan, että saamme oikeudet Xamkin Azuren Resource groupiin. Loimme sinne aluksi oman SQL-serverin, johon myöhemmin avattiin SQL database. Databasen synnyttyä selvitimme, miten sinne saa ladattua dataa, ja kuinka database käytännössä toimii. Seuraavaksi haasteeksi osoittautui datan saaminen. Meillä ei ollut mitään ladattavaksi sopivaa dataa, joten pyysimme apua toiselta projektiryhmältä. Toiselta ryhmältä saimme ns. testidataa, jolla pystyimme varmistamaan serverin toimivuuden. Onnistuneen datan siirtämisen jälkeen serveri oli valmis seuraavaan projektiin.
Kaikki vaiheet dokumentoitiin ja niistä koottiin lyhyitä oppaita opiskelijoita varten. Oppaita löytyy esim. Azure-serverin luomisesta, siirtämisestä, tiedon tuomisesta ja datan avaamisesta.
Vaadittavat ohjelmat
Serverin oikeanlainen toimiminen vaatii sen, että käyttäjältä löytyy tiettyjä ohjelmia. Meidän tilanteessamme ei vaadita monia ohjelmia, mutta niiden käyttö on pakollista. Parhaaksi ohjelmaksi datan lataamiseen ja muokkaamiseen serverille osoittautui Microsoftin SQL Server Management Studio, eli SSMS. Kyseisen ohjelman avulla pystyy vaivattomasti tarkastelemaan databasen sisältöä ja muokkaamaan sitä. Lisäksi ohjelma mahdollistaa sisällön lataamisen omaan databaseen.
Jotta datan avaaminen ja tarkastelu onnistuu, on parasta käyttää joko Microsoft Excel tai PowerBI -ohjelmia. Näiden ohjelmien avulla käyttäjä pystyy avaamaan koneellensa serverillä olevat datat ja muokkaamaan niitä. Ohjelmien avulla datan analysointi on myös mielestämme helpointa ja monipuolisinta.
Mitä jatkossa?
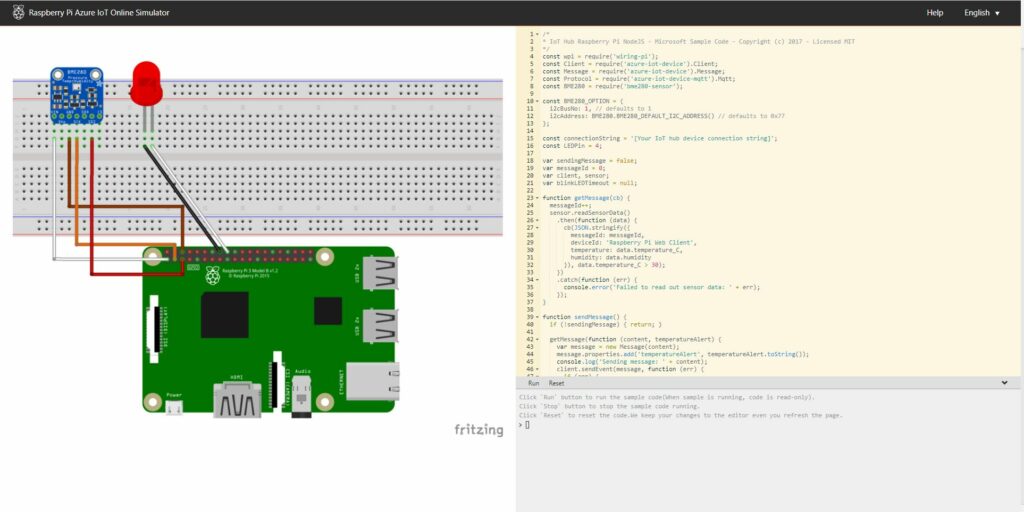
Tällä hetkellä meillä on toimiva pilvipalvelu, eli SQL-database. Pilvipalvelua voidaan hyödyntää opetuksessa ja erilaisissa projekteissa. Jatkossa tavoitteenamme on ladata srverille jatkuvasti päivittyvää, eli ns. livedataa. Dataa kerätään Raspberry Pi:n avulla. Kerätty data analysoidaan ja visualisoidaan PowerBI ohjelmalla. Olemmekin jo onnistuneesti testanneet sitä Raspberry Pi -simulaattorin avulla.
Kuten sadoissa muissa organisaatioissa, Kaakkois-Suomen ammattikorkeakoulussa käytetään Microsoftin ohjelmistoja ja palveluita. Teamsien ja powerpointtien lisäksi Data-analytiikka on ottanut käyttöönsä Microsoftin pilvipalvelualusta Azuren, josta löytyy monenlaista palvelua SQL-palvelimesta koneoppimismallien luomiseen.
Yksi palvelutyyppi on nk. kognitiiviset palvelut johon kuvien analysointi eli konenäkö kuuluu. Päätelmien tekeminen suuresta määrästä digitaalisia valokuvia niitä näkemättä tuntui mielenkiintoiselta ajatukselta. Azuren konenäössä on monenlaisia ominaisuuksia: on kasvojentunnistusta, kuvassa olevan tekstin tunnistusta, kuvien kategorisointia jne. Päätin lopulta kokeilla automaattista kuvatekstien ja tagien luomista valokuville jotta syntyisi jonkinlainen käsitys siitä miten se kuvia lajittelee.
Esimerkki automaattisesti generoidusta kuvatekstistä ja tageista. Tekstille ja jokaiselle tagille on myös konenäön tekemä ”confidence score”.
Testiaineistoksi valikoitui oppilaitoksemme Xamkin virallinen Instagram-tili ja sieltä 2000 valokuvaa.
Miten se toimii?
Konenäkö on API, eli ohjelmointirajapinta (Application Programming Interface). Yksinkertaisimmillaan sinne syötetään kuva ja kone palauttaa kuvalle pyydetyn datan (esim. tunnistetut kasvot, kuvauksen jne.) Tässä harjoituksessa käytin rajapintaa python-ohjelmointikielen avulla, jolle Microsoft tarjoaa kehitysalustan. Käytännössä Azureen perustetaan resurssi josta saa tarvittavan salasanan. Koodikirjastot tuodaan pythonin import-komennolla ja client autentikoidaan salasanalla, minkä jälkeen rajapintaan voi alkaa heitellä kuvia. Rajapinnasta on kattava ja johdonmukainen dokumentaatio.
Python-ohjelmointikielen tarvittavien koodikirjastojen tuonti ja clientin autentikointi konenäölle ja kasvojentunnistukselle.
Päätin hakea kuvatekstit ja tagit 2000 kuvalle ja liittää saadut tulokset osaksi Instagram-aineiston metadataa. Kahden tuhannen kuvan läpikäynti kestää koneelta jonkin aikaa, joten kerkesin käydä välillä lounaalla ja palata sitten katsomaan mitä tuloksista mahdollisesti voi saada irti.
Ja toden totta, tekoäly oli keksinyt kuville englanninkieliset kuvatekstit ja tagit. Azuressa olisi mahdollista myös kääntää tekstit automaagisesti suomeksi mutta tämä vaatisi lisää API-kutsuja, joten päätin pärjätä kolmannella kotimaisella. Analyysissä käytin pythonin pandas-kirjastoa jossa data on taulukkona (dataframe) ja sen filtteröintiin ja muokkaamiseen on paljon tehokkaita työkaluja.
Polkupyöräkuvien etsiminen – with confidence
Tagien avulla suuresta kuvamassasta voi hakea tiettyjä elementtejä sisältäviä kuvia. Kokeilin hakea 2000 kuvan joukosta ne, joissa on tägi ”polkupyörä” (eli siis bicycle). Tuloksista selvisi, että Bill Gatesin robottisilmälasit ovat nähneet yhteensä 27 kuvaa joissa on polkupyörä.
Suodatin polkupyöräkuvat tykkäysten mukaan alenevaan järjestykseen ja katsoin mitä kone on oikein nähnyt. Aluksi kaikki vaikuttaa hyvältä. Esimerkiksi 157 tykkäystä saaneessa, Vappua juhlistavassa kuvassa on selkeästi polkupyörä ja kone antaa ’bicycle’ -tagille confidence scoren 0.9501 mikä on todella kova.
Koneen mielestä tässä kuvassa on polkupyörä yli 95 % luottamustasolla.
Seuraavassa kuvassa ei kuitenkaan ole polkupyörää. Siinä on polkupyörä-tägi ja mies hymyilemässä jonkinlaisen osittain näkyvän metalliputkihässäkän luona mikä aivan ilmeisesti ei ole polkupyörä. Kuvan bicycle-tag onkin saanut confidence scoren 0.31. Luokittelua varten päätin rajata pisteytyksen 0.9 ja sitä suurempiin lukuihin. Tätä varten pandasilla on helppo luoda uusi taulukko kuvista, joissa on mukana vain tagit joiden luotettavuusarvo ylittää 0.9. Polkupyörien kohdalla tämä toimii mainiosti ja lopulta onnistun etsimään kaikista kuvista vain sellaisia, joissa oikeasti on pyörä. Lisäksi on tuntematon määrä kuvia joissa on pyörä mutta jotka eivät saa polkupyörä-tagia.
Julkiset naamat
Lievänä yllätyksenä tuli, että kuvatekstitoiminto tunnistaa julkkisten naamoja. Azuressa on erikseen kasvojentunnistin, jolla kasvoille voi generoida tunnisteen. Tunnisteen avulla samanlaisia kasvoja voi etsiä kuva-aineistoista. Kuvateksti-toiminto kuitenkin löytää suvereenisti suomalaisia julkkiksia. Koska Xamk on vahvasti mukana Emma-gaalassa, päätin katsoa onko gaalakuviin tallentunut julkisia naamoja. Etsinnässä auttaa myös tässä yhteydessä käytetty hashtag ”xamkgoesemma”. Keinosilmät ovat nähneet mm. 3 Anna Puuta, Reino Nordinin, Juha Tapion, Sanni Kurkisuon ja Erkki Liikasen (joista viimeinen ei ehkä Emma-gaalasta).
Kuvassa Pyhimys puvussa. Tekoälyn mielestä kyseessä on 0.563 todennäköisyydellä ’gentleman’.
Yksi hämmentävä ilmiö ovat julkkisten kaksoisolennot. Kone löysi Xamkin Instagramista useita ulkomaisia julkkiksia, jotka lähemmässä tarkastelussa osoittautuivat tavallisiksi tallaajiksi jotka vain sattuvat näyttämään julkkiksilta.
Scoreissa on eroja
Luottamuspisteytykset jotka kone ilmoittaa kuvateksteille ja tageille poikkeavat ratkaisevasti toisistaan. Kuvateksti joka saa pisteytyksen 0.5 on usein ”oikein” ja jopa hyödyllinen, kun taas jos haluaa luokitella kuvia tagien avulla niin 0.5 tasoa ei välttämättä kannata ottaa mukaan.
Ero käy ilmi myös luottamustasojen jakaumasta. Tarkastelin kuvatekstien ja tagien saamia pisteitä tekemällä niistä box-plotit pandasissa:
kuvat['caption_confidence'].plot(kind='box', vert=False, figsize=(10,5), title = 'caption_confidence')
Datassa on 2000 koneen generoimaa otsikkoa. Mediaani on alle 0.5:ssä. Silläkin tasolla otsikot ovat kuitenkin usein ”oikein”.Kahdessatuhannessa kuvassa on hieman alle 18000 tagia (n.9kpl/kuva) 25. ja 75. persentiilit asettuvat välille 0.7-0.94 mediaanin ollessa 0.869.
Konenäön tekemän luokittelun luotettavuuden arvioinnissa koneen ilmoittamat pisteytykset ovat hyvä apuväline. Erityisen mielenkiintoista on etsiä tageja joista kone on omasta mielestään lähes varma, mutta jotka kuitenkin ovat päin honkia.
Seuraavia harjoitteita
Kuvatekstigeneraattorin kyvystä tunnistaa julkisuuden henkilöitä syntyi ajatus syöttää konenäölle julkisuuden henkilöitä. Suunnitelmissa on käyttää kotimaisten digitaalisten viihdeuutisten kuvastoa ja analysoida keitä se tunnistaa ja keitä ei. Jatkuu seuraavassa numerossa.