Kokonaisuudessaan harjoitteluni koostui useasta osasta. Minulla oli hieman aikaisempaa työkokemusta, jota kykenin hyödyntämään osana perusharjoittelua. Lopun perusharjoittelun ja syventävän harjoittelun suorituspaikkana toimi DataLAB, jossa työskentelin muutaman isomman projektin ja tehtävän parissa. Harjoittelun suoritin toukokuun 2021 ja joulukuun 2021 välillä.
Hävikki-projekti
Hävikki-projektiin haettiin data-analytiikan opiskelijaa keväällä 2021. Projekti oli kuvauksen perusteella kiinnostava ja mikä tärkeintä, siinä pääsi vaikuttamaan oikeisiin ja olemassa oleviin ongelmiin. Projektin tarkoitus oli selvittää vähittäistavarakaupoista kerättävän datan avulla, voiko ruoan hävikkiä ennustaa.
Pitkälti projektin työkaluna toimi R-studio. Projektin ensimmäisessä vaiheessa hävikkiä ennustettiin regressiomallien avulla. Projektin toisessa vaiheessa saatiin lisää dataa käyttöön ja lähestymistapaa vaihdettiin. Hävikin esiintyvyyttä alettiin tarkastelemaan keskiarvon ja keskihajonnan avulla, joita laskettiin sitä mukaa kun päiviä kertyi. Tällä tavoin ennusteen tarkkuus parani, mitä enemmän dataa saatiin kerättyä.
Hävikki-projekti sai myös jatkoa syksyllä 2021 data-analytiikan opintoihin sisältyvän projektin yhteydessä. Projektin tarkoituksena oli löytää sopiva määritelmä ongelmallisille tuotteille, joilla on suurempi riski aiheuttaa hävikkiä.
Kesätehtävät
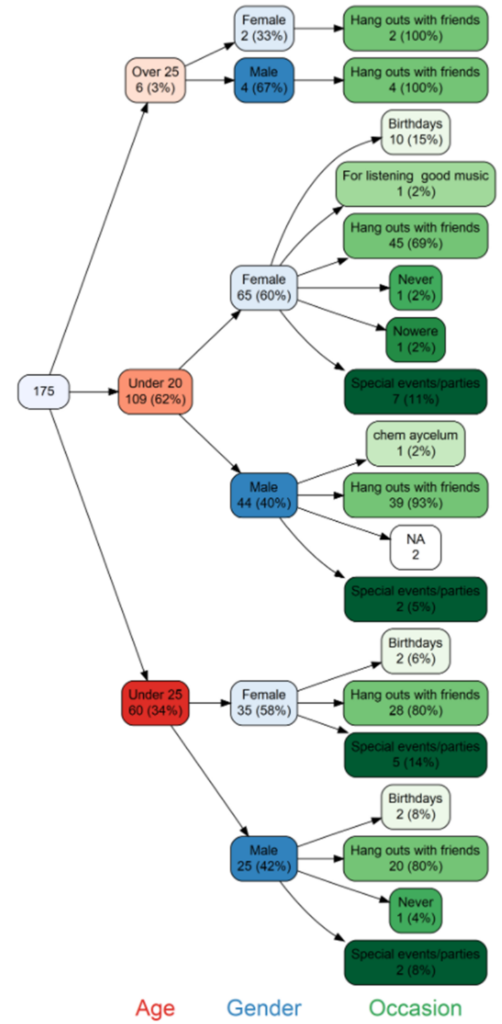
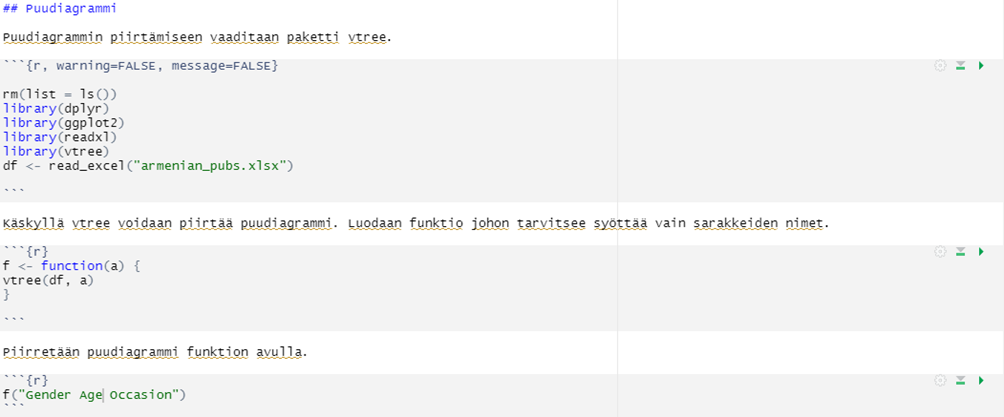
Kesän ajaksi sain kolme isompaa tehtävää suoritettavaksi. Ensimmäisenä tehtävänä oli luoda frekvenssejä kuvaava puudiagrammi hyödyntäen R-Studiota. Esimerkiksi kyselytutkimuksen analysoinnissa voi olla hyödyllistä käyttää puudiagrammia, sillä se kuvaa selkeästi muuttujien jakautumista sekä näyttää lisäksi niiden arvot ja frekvenssit. Kirjoitin aiheesta myös erillisen blogin: Frekvenssejä kuvaava puudiagrammi.
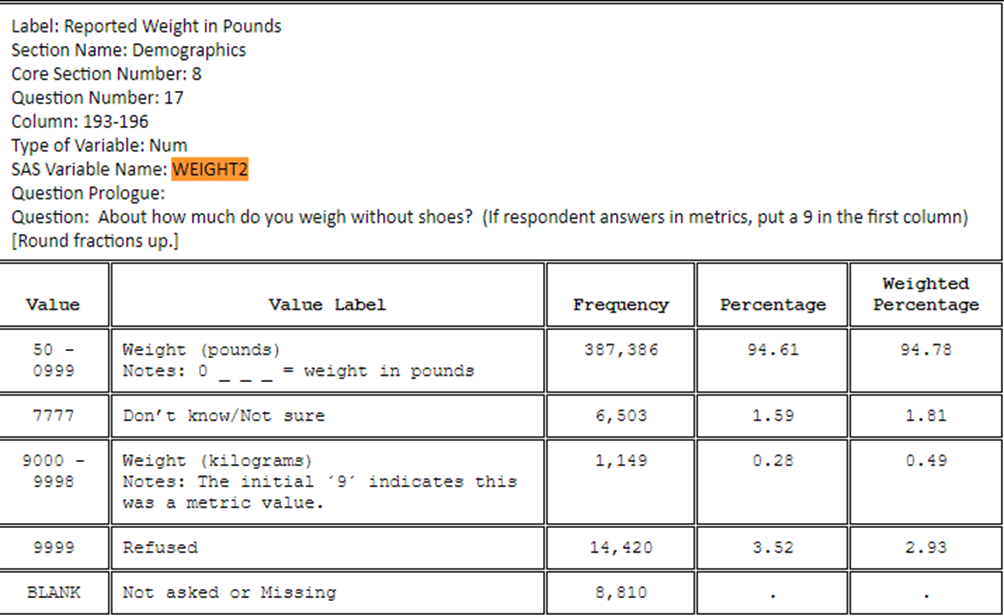
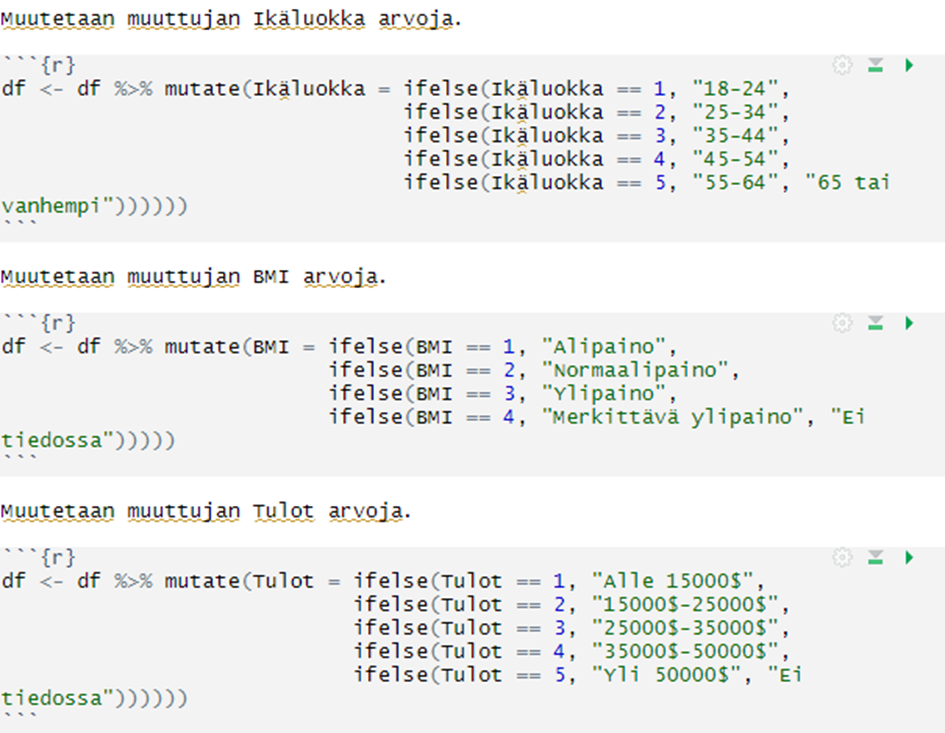
Toinen kesätehtäväni oli muokata BRFSS-data kyselytutkimusainestoa vuodelta 2019, jossa on tutkittu Yhdysvaltain kansalaisten terveyttä ja elintapoja. Tarkoituksena oli saada aikaan selkeämpi ja suomennettu kokonaisuus, joka sisältää jatkuvia ja epäjatkuvia muuttujia hyödyntäen R-Studiota. Tarkemmin muokkauksesta kerron blogissa: BRFSS-datan muokkaus.
Kolmas kesätehtäväni oli R-Studion avulla tarkastella logistista regressiota. Tehtävänä oli esitellä logistisen regression teoriaa, mallin tekeminen, ennustaminen ja selvittää mallin toimivuus. Tehtävässä hyödynsin aiemmin muokkaamaani BRFSS-dataa.
Muuta
DataLAB pitää sisällään myös muita työtehtäviä. Niihin kuuluu kuukausittaiset palaverit, joissa käydään läpi sen hetken työtilanteita ja jatkotoimenpiteitä. Kouvolan kampukselle avatun FUEL-tila myötä myös DataLAB sai fyysiset toimitilat syksyllä 2021. Olin itse mukana tekemässä muuttoa ja järjestelyitä uusissa tiloissa. DataLAB piti FUEL-tilan avajaisissa myös omaa pistettä, jossa esiteltiin aikaan saatuja töitä. Omalta osaltani esittelin keväällä 2021 tehtyä Hävikki-projektia.
Lopuksi
Harjoittelusta opin paljon. Tehtävät olivat välillä haastavia, mutta koen sen olleen myös suuri etu. Hienoa oli myös päästä vaikuttamaan oikeisiin ongelmiin sekä nähdä oma työnsä jälki, ja että siitä oli myös hyötyä. DataLAB tarjoaa monipuolisia työtehtäviä opiskelijoille, joten siellä harjoittelun suorittamista kannattaa ehdottomasti pitää mahdollisuutena.