Xamkin DataLAB:ssa on käynnissä mielenkiintoinen projekti osana AIRA-hanketta, ja sen tuloksena on syntynyt visuaalinen Power BI -raportti hätäkeskusdatasta. Mutta mistä tässä kaikessa on oikein kyse?
AIRA-hanke
Pelastustoimen ja alueellisen varautumisen tehtävänä on parantaa valmiutta uhkiin ja ennakoida riskejä jo ennen kuin ne konkretisoituvat. Tämä työ on tällä hetkellä pitkälti manuaalista ja hajanaista sekä vaatii jatkuvaa yhteistyötä eri toimijoiden välillä, sillä käytössä ei ole yhteistä tietopankkia tai analyysityökalua.
AIRA hyödyntää tekoälyä ja data-analytiikkaa tehostaakseen riskianalyysien tekoa ja tiedolla johtamista. Tavoitteena on vähentää manuaalista työtaakkaa ja parantaa yhteistyötä sidosryhmien välillä. Lisäksi tarkastelussa on, kuinka riskejä voisi tunnistaa aiempaa tehokkaammin, ja suunnitella alueellista kokonaisturvallisuutta parantavia toimenpiteitä.
Hanke hyödyttää konkreettisesti eri toimijoita, kuten pelastustoimia ja poliisia, jotka tarvitsevat työssään tarkkaa ja ajantasaista tietoa päätöksenteon tueksi ja yleisen turvallisuuden ylläpitämiseksi.
Täältä voit lukea aiheesta lisää: https://www.xamk.fi/hanke/aira/
DataLAB-projekti
Tiesitkö, että Suomessa eniten hälytyksiä tulee kesäkuussa ja perjantaisin? Xamkin DataLAB:ssa käynnissä olevassa projektissa on hyödynnetty hätäkeskusdataa, joka kattaa tiedot siitä, mitä on tapahtunut ja missä, ajanjaksolla tammikuu 2015 – helmikuu 2025. Rivimuotoista dataa on kuitenkin hankalaa hahmottaa nopealla vilkaisulla. Siksi sen pohjalta rakennettiin kolmisivuinen Power BI -raportti, joka havainnollistaa hälytysten määrää, ajankohtia ja alueellista jakautumista visuaalisesti ja helposti tulkittavassa muodossa.
Projektin datan valmistelu
Hätäkeskusdata sisältää sarakkeet paikkakunnasta, kellonajasta ja päivämäärästä, tehtävän kuvauksen, yksityiskohdat, linkin uutiseen ja hätäkeskuskoodin. Projektia varten myös hätäkeskuksen nimen sisältävä sarake oli tarpeen, ja se luotiin hyödyntämällä SQL-kyselyä Microsoft Visual Studiossa. Azuren tietokannassa oleva data yhdistettiin Power BI:hin, jossa raportin teko alkoi. Raportin visuaalinen ilme on rakennettu Xamkin brändivärien ympärille hyödyntämällä HEX-värikoodeja, ja DAX-kaavojen luomisessa apuna ovat olleet ChatGPT ja Claude.ai.
Raportti sivu kerrallaan
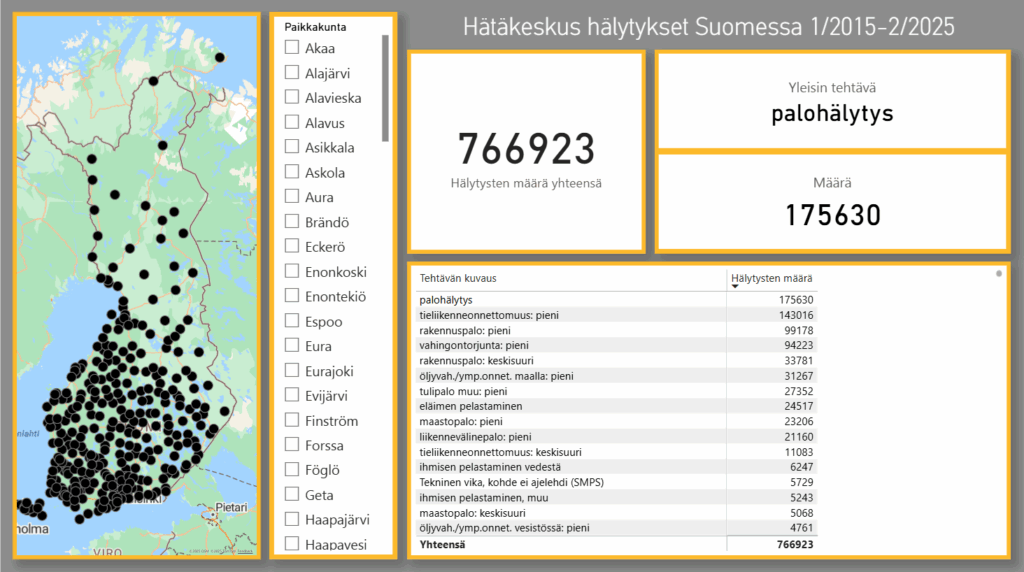
Ensimmäisellä sivulla voi tarkastella hälytyksiä paikkakuntakohtaisesti. Sivulla on kartta, slicer, taulukko ja kortteja. Kartassa näkyy valitun paikkakunnan sijainti, ja paikkakunnan voi valita viereisestä slicer-visuaalista. Kaikki sivun visuaalit reagoivat sliceriin, joten tietoja voi tarkastella paikkakuntakohtaisesti. Korteissa näkyy hälytysten yhteismäärä sekä yleisin tehtävänimike ja sen määrä. Yleisin tehtävä koko Suomessa on ollut palohälytys, joita on ollut vuosien varrella yhteensä 175 630 kappaletta. Kaikenlaisia hälytyksiä on ollut yhteensä 766 923, joka tarkoittaa keskiarvollisesti yli 200 hälytystä joka päivä noin kymmenen vuoden tarkastelujakson aikana.
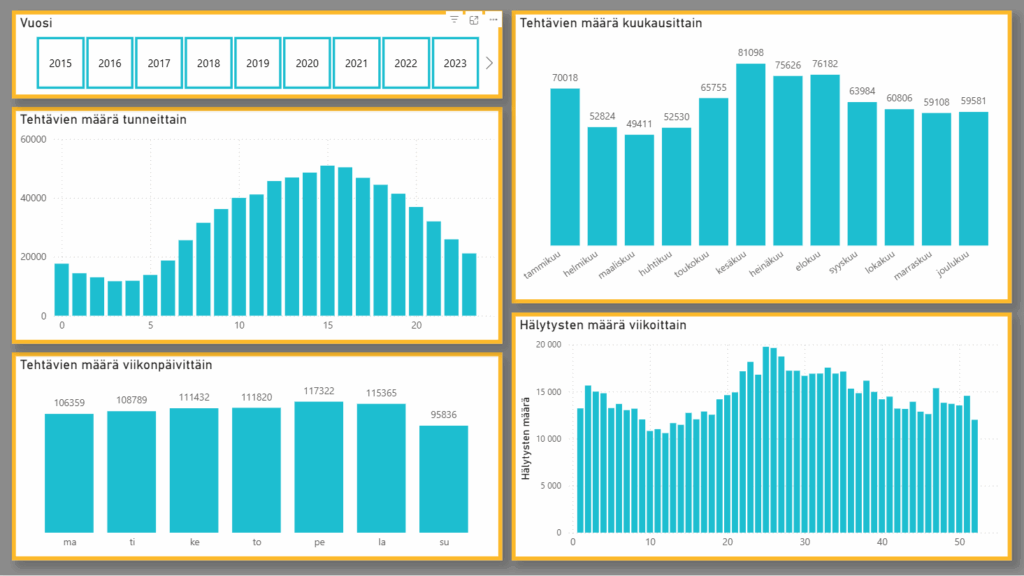
Toisella sivulla pureudutaan hälytyksiin ajallisesti. Hälytysten määrää voi tarkastella vuosittain, kuukausittain, tunneittain, viikonpäivittäin ja viikottain, joille jokaiselle löytyy oma visuaali tai slicer sivulta. Esimerkiksi valittaessa slicerista vuodeksi 2018, voidaan huomata tehtävien määrän olleen korkeimmillaan kesäkuussa (9426 tehtävää) ja eniten tehtäviä on tullut kello 16 aikaan. Tehtäviä on tullut eniten perjantaisin, ja selkeästi eniten hälytyksiä koko vuonna on tullut viikolla 25. Tämä on ollut juhannusviikko, jossa tehtävät ovat myös pitkälti keskittyneet perjantaihin eli juhannusaattoon.
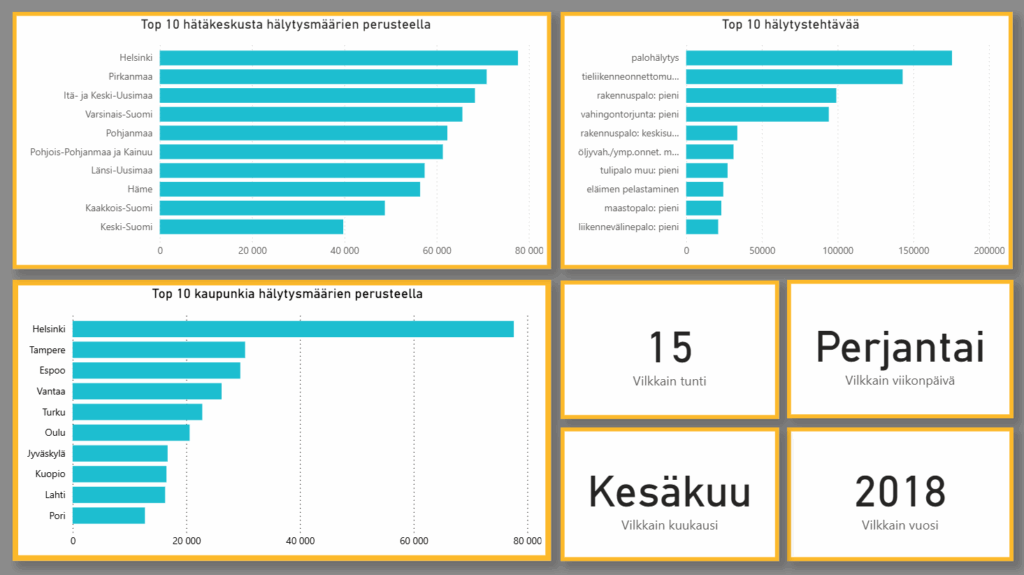
Sivulta kolme löytää raportin Top 10 -listat. Määrällisesti eniten hälytyksiä on ollut Helsingissä, yhteensä 77 632 tehtävää. Helsinki vie myös top 1 sijan kaikista hätäkeskuksista hälytysmäärien perusteella, sijalla kaksi on Pirkanmaan hätäkeskus ja kolmannella Itä- ja Keski-Uudenmaan hätäkeskus. Eniten hälytystehtävissä törmää palohälytyksiin, tieliikenneonnettomuuksiin ja pieniin rakennuspaloihin. Vilkkain tunti vuosien varrella on ollut kello 15, eniten hälytyksiä on tullut perjantaisin, kesäkuut ovat olleet tapahtuma-alttiimpia kuukausia, ja hälytysmäärien perusteella eniten on tapahtunut vuonna 2018.
Lopuksi
Kuten huomata saattaa, hälytykset pitävät ammattilaiset kiireisinä päivittäin, mutta data paljastaa erityisen tapahtuma-alttiit kuukaudet, viikonpäivät, viikot, tunnit ja alueet. Lisäksi hälytykset voidaan lajitella tyypin yleisyyden mukaan. Raportin avulla voidaan helposti nähdä, millaisia hälytyksiä voidaan odottaa tulevan eniten ja milloin. Tämä auttaa keskittämään voimavarat sinne, missä niitä milloinkin eniten tarvitaan.
Linkki raporttiin: https://app.powerbi.com/groups/3d571500-7ded-46fd-99a2-a6399208b83b/reports/899f056b-ee1a-41d8-89ae-df2e3b76e09a/edfb6b0ddd1840ca89b8?experience=power-bi
Huomaa, että raportti näkyy vain Xamkilaisille.