Kymmenellä rivillä koodia joista osa on turhia
Python
Tässä blogitekstissä kerrotaan miten redditistä voi kerätä dataa käyttämällä yksinkertaista python ohjelmaa. Sen käyttö ei vaadi koodausosaamista, riittää jos osaa tehdä python asennuksen ja avata tiedoston mukana tulevalla työkalulla.
Datan keräämiseen tarvitaan siis python-ohjelmointikielen asennus tietokoneelle. Kätevän ja jokseenkin pöhöttyneen ratkaisun tarjoaa Anaconda ja sen voi asentaa tietokoneelleen täältä.
Kun kärmes on asennettu, voidaan siirtyä datan keräämiseen. Tässä esimerkissä käytetään Pushshift APIa sekä sille räätälöityä python kirjastoa nimeltä psaw. Jos ei jaksa lukea blogitekstiä niin koodi löytyy datalabin githubista täältä.
Psaw-kirjasto täytyy asentaa ennen sen käyttämistä. Anacondan (ja vähemmän pöhöttyneen minicondan) mukana tulee python pakettien asentaja nimeltä pip, ja tarvittavan paketin voi asentaa kirjoittamalla anacondan komentoriville komento pip install psaw
Vihko
Koodi on kirjoitettu internet-selaimessa pyörivään Jupyter-vihkoon. Sen voi käynnistää joko anacondan valikosta tai kirjoittamalla jupyter notebook promptiin. Githubista löytyvän vihkon voi avata omalla koneella ja tehdä redditiin hakuja muuttamalla hakuparametrejä mieleisekseen (ja lisäämällä uusia). Pushshift API tarjoaa useita tapoja rajata haettavaa dataa. Esimerkiksi parametrillä q voi postauksen otsikkoon tai tekstiin kohdistaa sanahakuja, mutta tässä käytetään vain seuraavia parametrejä:
- after: ajankohta jonka jälkeen postauksia haetaan (VVVV-KK-PP)
- before: ajankohta johon asti postauksia haetaan
- subreddit: alareddit josta haetaan
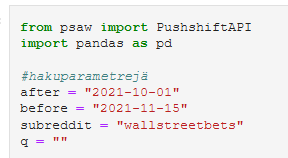
Haku tehdään postausten (submission) endpointiin ja kohdennetaan r/wallstreetbets alaredditiin. Se on aktiivinen yhteisö joka tunnetaan mm. äkillisestä innostuksesta ostaa Gamestop-yrityksen osaikkeita alkuvuodesta 2021.
Testissä haetaan postauksia puolentoista kuukauden ajalta lokakuun alusta marraskuun puoleenväliin 2021 ja niitä löytyi hieman yli 41 000, eli n.900 kpl/päivä.

Nopeata tarkastelua varten postausten data laitetaan Pandas-kirjaston avulla luotuun taulukkoon. Esimerkissä taulukko on nimetty nimellä df, joka on lyhenne sanoista DataFrame. Pandas kirjasto löytyy valmiina anacondasta. Taulukon voi muuttaa helposti esimerkiksi csv-tiedostoksi komennolla df.to_csv('myRedditDataCsv.csv')
Palkkikaavio
Seuraavaksi dataa analysoidaan värikkäällä palkkikaaviolla. Redditissä postauksella voi olla ”flair” joka on käyttäjän sille lisäämä luokittelu ja josta käy ilmi postauksen aihe. Joissain alaredditeissä sellainen vaaditaan kun taas joissain sitä ei käytetä ollenkaan. Kerätyssä datassa flair on muuttuja nimeltä "link_flair_text” ja pandas-taulukosta voi nopeasti tarkastaa, että kerätyissä postauksissa kyseinen sarake saa vain 15 Null -arvoa. Tämä kertoo siitä että kyseisessä alaredditissä postausten merkitseminen flairilla on todennäköisesti pakollista.
Eri flairien määrät on visualisoitu aina trendikkäällä palkkikaaviolla.

Tuloksista näkee, että flaireja on postausten määrään nähden vähän, mikä todennäköisesti johtuu siitä että ne valitaan valmiista listasta eikä niitä voi keksiä itse.
Koodi löytyy siis Xamkin datalabin githubista. Onnistuneen python asennuksen jälkeen koodia voi pyörittää omalla koneella painamalla play-nappia. API:n avulla voi selvittää esimerkiksi miten monta kertaa iltasanomien url on jaettu Redditissä,kerätä kaikki kuva-urlit r/historymemes -yhteisöstä tai vaikka kaikki koronamegaketjuihin tehdyt kommentit.





