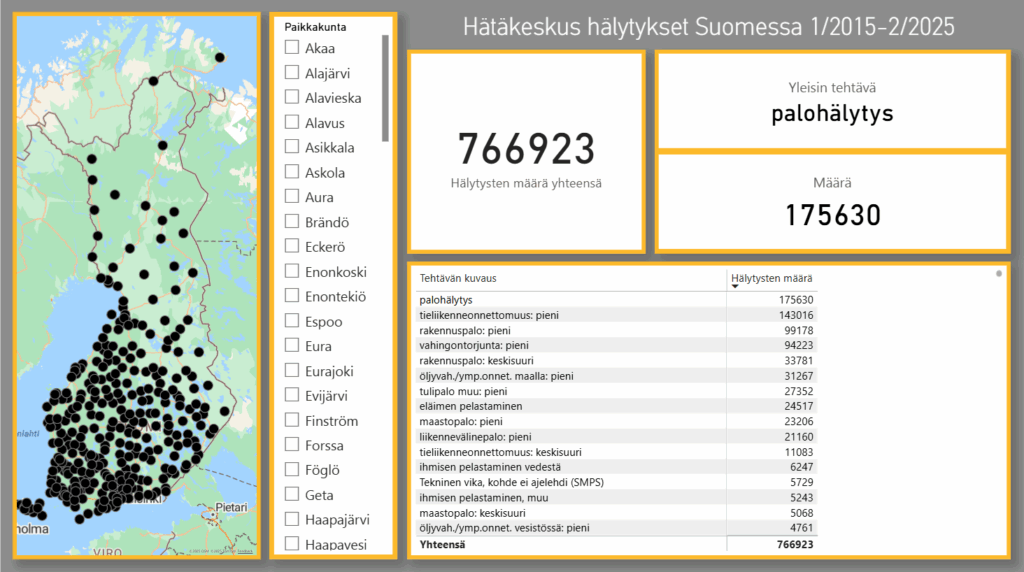
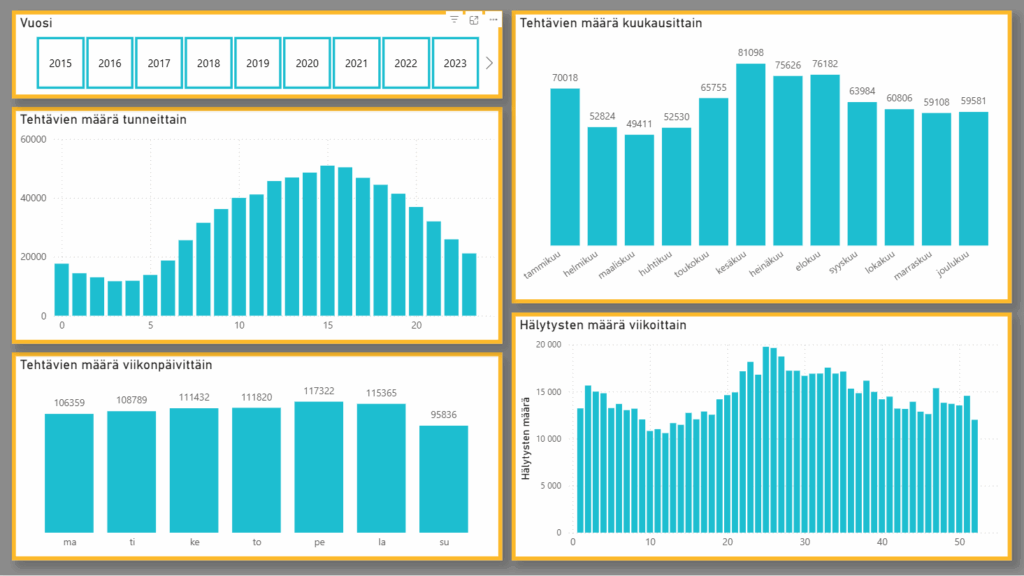
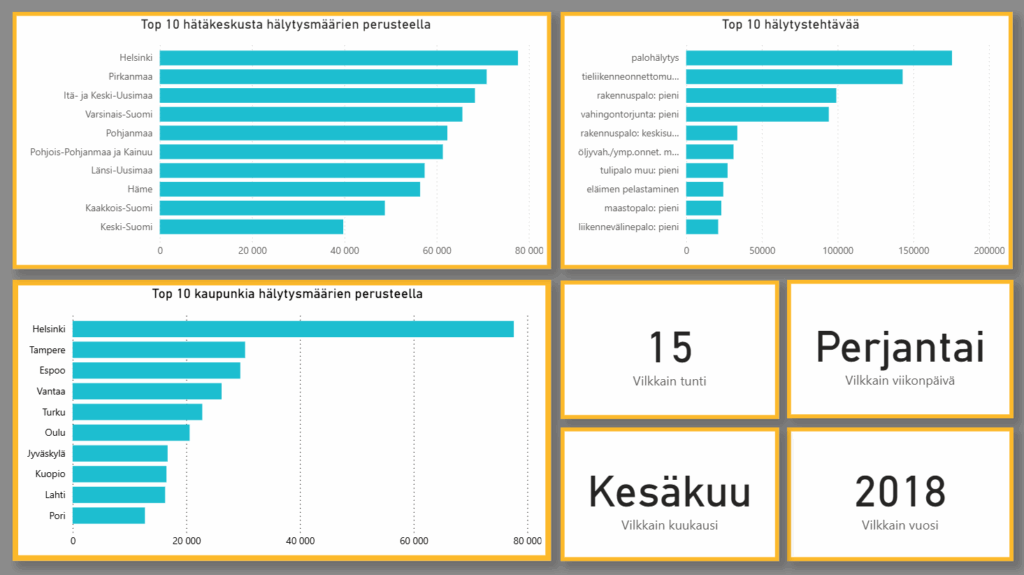
DataLabiin suoritettavana syventävänä harjoitteluna tehtäväkseni valikoitui Seaborn-oppaan luominen. Tarkoituksena oli luoda selkeä ohjeistus, jonka avulla Python-ohjelmointikielellä tehtäviä visualisointeja pystyisi tekemään myös sellaiset, joilla ei ole aiempaa ohjelmointiosaamista. Oppaassa käytettiin tekoälytyökalu Copilotin apua Python-koodien kirjoittamiseen.
Toteutus
Ensin piti valita missä ympäristössä työ haluttiin toteuttaa. Kokeiltiin Google Colabia sekä Jupyter Notebookia, valittiin Jupyter. Vaikka Colab oli monien netistä löytyvien oppaiden suositus, Notebook koettiin helppokäyttöisemmäksi, erityisesti aloittelijan näkökulmasta. Työssä pyrittiin pitämään mielessä miten data-analytiikan muilla kursseilla, kuten Power BI, käsiteltiin datan visualisointia ja haluttiin kokeilla miten samantyyppinen toteutettaisiin Seaborn-kirjaston avulla. Seabornin virallinen opas oli merkittävä apuväline työn toteutukseen, mutta vaatii lukijalta jonkin verran pohjatietoa aiheesta. Oppaassa käytettiin ERP-simulaatiopelistä saatua kaupallista dataa.
Visualisoinnit
Visualisointien koodit pyydettiin tekoälyltä Python-koodina. Usein koodissa oli jotain muokattavaa, jotta se saatiin halutunlaiseksi ja tekoälyn kanssa jouduttiinkin keskustelemaan pitkään halutun lopputuloksen saamiseksi.
Visualisoinnit jaettiin seuraaviin osioihin:
- Tilastolliset visualisoinnit
- Relaatiokaaviot
- Kategoriset kaaviot
- Jakaumien visualisointi
- Moniulotteiset visualisoinnit
- Lineaariset regressiomallit
Opas aloitettiin melko yksinkertaisilla Python-koodilla tehtävillä kuvaajilla, joista edettiin koko ajan vaativampiin visualisointeihin. Viimeisin osio lineaarisista regressiomalleista vaatiikin jo hieman taustatietoa tilastotieteestä. Esimerkeissä pyrittiin käyttämään sellaisia muuttujia, jotka ovat kaupallista dataa analysoitaessa tärkeitä. Oppaassa käytetyn datasetin Sales-välilehti sisälsi merkityksellisimmän osan tiedosta tähän liittyen.
Kun kyseessä on suuri datamäärä kuvaajien muodostuminen saattaa kestää kauan. Tällaisissa tilanteissa voidaan harkita otoksen ottamista datasta, jolloin oppaan esimerkin mukaan koodi: data=df_sales.sample(300) valitsee datasta 300 satunnaista havaintoa. Oppaassa on myös suodatettu dataa esimerkiksi suurimpien ja pienimpien arvojen mukaan, jolloin voidaan verrata esimerkiksi hyvin ja huonosti menestyvien eroja.
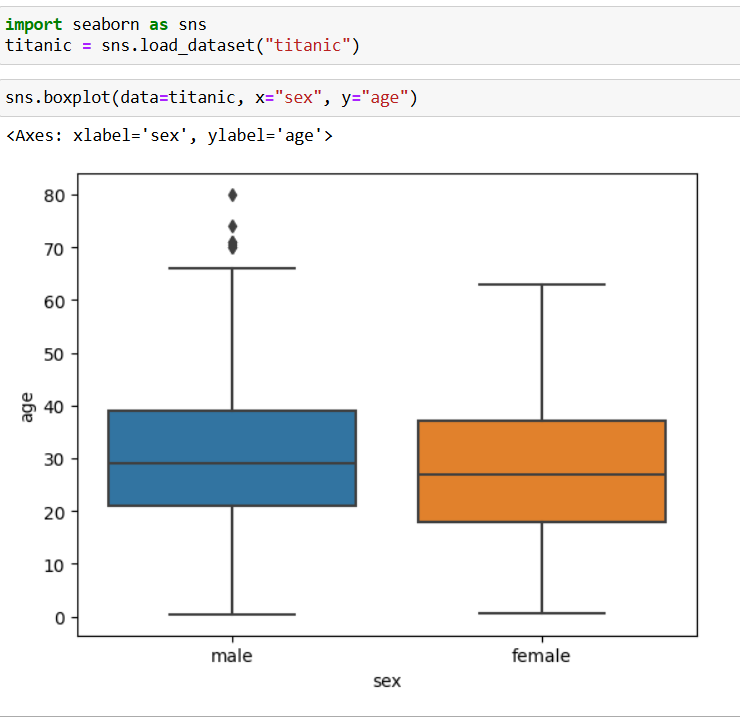
Seaborn-visualisointeja pääse helposti kokeilemaan, koska se sisältää valmiita datasettejä. Esimerkiksi Titanic-dataa sisältävä datasetti saadaan työkirjaan koodilla titanic = sns.load_dataset(”titanic”). Näin pääsee heti kokeilemaan miltä Seaborn-visualisoinnit näyttävät eikä tarvitse pohtia, mistä löytyisi sopiva ja puhdas data harjoitteluun. Tässä esimerkki ikäjakaumasta sukupuolen mukaan.
Linkki oppaaseen Opas Seaborn-kirjaston hyödyntämiseen bisnesdatan visualisoimisessa — Kirja
Visualisointien tyyli
Seabornin avulla saadaan ammattimaisen näköisiä visualisointeja lähes automaattisesti, se luotiinkin juuri ajatuksena, että käyttäjä voisi keskittyä kuvaajan analysointiin ei sen piirtämiseen. Kuvaajia voi kuitenkin halutessaan muokata monin tavoin. Tämän esimerkin oikeanpuoleinen kuvaaja on ilman tyylimuotoiluja tehty pylväsdiagrammi ja vasemmalla olevaan on muokattu otsikoita ja väritystä.
Tekoälyn avulla kirjoitetut koodit kannattaa aina tarkistaa ennen niiden ajamista erityisesti jos on tarkka millaisen visuaalisen muodon haluaa kuvaajalle. Microsoftin Copilot lisää usein pyydettyyn koodiin omia muokkauksia, välillä vaikka koodi pyydettäisiin ilman niitä.
Lopuksi
DataLabille suoritettuna harjoittelu vaatii opiskelijalta erityisesti ajankäytön hallintaa sekä motivaatiota saavuttaa itselleen asetetut tavoitteet. Aiheen olisi hyvä olla opiskelijalle aidosti mielenkiintoinen, sillä itsenäinen työskentely edellyttää todellista kiinnostusta ja halua oppia enemmän. Pythonin ja Seabornin lisäksi opin myös paljon erilaisia tapoja hyödyntää Jupyter-ympäristöä, jonka uskon tulevan hyödyksi vielä myöhemmin.